一文搞懂Batch Normalization,Layer/Instance/Group Norm - 知乎 (zhihu.com)
BN – Batch Normalization
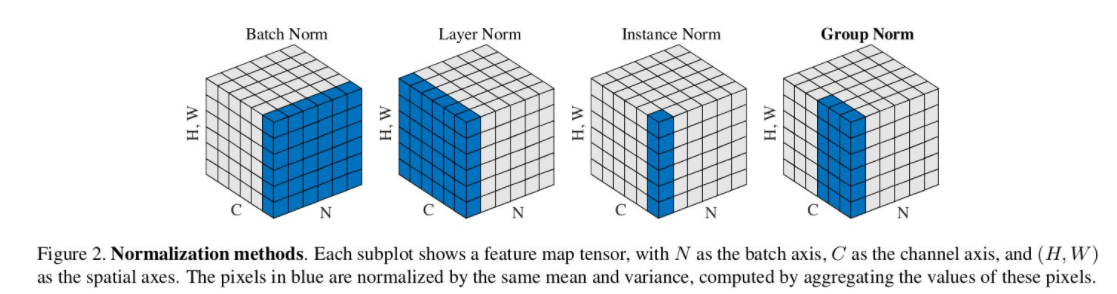
上面的演示图是专门针对卷积网络的。如果是一般的数据 $x$ , 第一个维度通常是 batch, BN 就是在 batch 上面做归一化。举例:$x : (32, 784)$ (一个batch 大小为 32 的 MNIST 数据摊平),如果做 BN, 就需要计算 $784$ 个 $\mu, \sigma$。
Figure 2 里面的 BN 是在 batch 和 HW (也就是图片的大小) 这两个维度上做 BN 。还是拿 MNIST 举例子,比如原来 $(32, 1, 28, 28)$ 的 MNIST 数据输入卷积网络之后在中间变成了 $(32, 64, 14, 14)$ 的 feature maps , 那么 BN 就需要计算 $64$ 个 $\mu, \sigma$ 。这里的假设是卷积特征的 invariant 的特性。具体来讲,一个 example 的某一张 feature map ,是用一个卷积核在之前的 feature maps 上面进行扫描得到的,所以各个地方的 response 可以认为他们服从相同的 distribution。所以可以放到一起去计算 $\mu, \sigma$ 。
GN+WS – Group Normalization + Weight Standardization
Layer Norm 比较极端,要对每一个 example 里面的所有 feature 做归一化,沿用上面的例子,$(32, 64, 14, 14)$ , 每一个 example 就是 $(64, 14, 14)$ 的 feature maps, Layer Norm 要计算这些数据的 $\mu, \sigma$ , 然后进行归一化。
Instance Norm 是另一个极端,他把 channel 独立了出来,也就是每张 feature map 单独进行 normalization. 上面的例子中, 每张 feature map 的大小是 $(14, 14)$ ,那 Instance Norm 就要计算 $1414$ 个数据的 $\mu, \sigma$ , 然后进行归一化。当然,对于一个 batch, 就有 $3264$ 个 $\mu, \sigma$ 需要计算。
Group Norm 是 Layer Norm 和 Instance Norm 的结合版,当然看起来也不是很高级。他就是把所有的 channel 分了组 (group)。 上面的 $64$ 个 channel, 分成 $4$ 组, 每组就是 $16$ 张 feature map. 计算的时候, 这些分组的 channel 都是默认按照连续的。 而且, group 的数量是需要手工指定的, 这就引进了新的 hyper param, 提高了炼丹训练的难度。
WS 的 pytorch 代码实现:
class Conv2d(nn.Conv2d):
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, groups=1, bias=True):
super(Conv2d, self).__init__(in_channels, out_channels, kernel_size, stride,
padding, dilation, groups, bias)
def forward(self, x):
weight = self.weight
weight_mean = weight.mean(dim=1, keepdim=True).mean(dim=2,
keepdim=True).mean(dim=3, keepdim=True)
weight = weight - weight_mean
std = weight.view(weight.size(0), -1).std(dim=1).view(-1, 1, 1, 1) + 1e-5
weight = weight / std.expand_as(weight)
return F.conv2d(x, weight, self.bias, self.stride,
self.padding, self.dilation, self.groups)
思路也非常简单,就是对每一个 filter 的 weight 做归一化 (bias 没有)。
paper 里面也展示了在一些任务里面, GN+WS 能够取得比 BN 更好的性能。
比较
两种方案最大的不同就是 GN+WS 能够适用于 batch_size 特别小的情况 (尤其是在当前和今后的分布式训练的场景中,加上 model 和 example 都越来越大,比如 video)。而 BN 在 batch_size 小的时候不能获得足够的统计数据,导致模型的性能下降很厉害。
而且 BN 还需要在训练的时候记录所有数据的 $\mu, \sigma$, 这样才能在 inference 时候也对 data 进行近似的 normalization. 而 LN, IN, GN 则不需要这么做。